The power and beauty of in-memory computing projects are that they truly do what they state -- deliver outstanding performance improvements by moving data closer to the CPU, using RAM as a storage and spreading the data sets out across a cluster of machines relying on horizontal scalability.
However, there is an unspoken side of the story. No matter how fast a platform is, we do not want to lose the data and encounter cluster restarts or other outages. To guarantee this we need to somehow make data persistent on the disk.
Most in-memory computing projects address the persistence dilemma by giving a way to sync data back to a relational database (RDBMS). That sounds reasonable and undoubtedly works pretty well in practice, but if we dig deeper, you’ll likely encounter the following limitations:
- RDBMS is a bottleneck. No matter how fast your in-memory technology project, you can accelerate read operations only because every write has to be persisted to the disk -- which is usually a single machine running an RDBMS instance.
- RDBMS is a single point of failure. Your distributed in-memory cluster usually consists of dozens and even hundreds of nodes which means you can safely lose this node here or drop that node there without worrying about data consistency and availability. However, if the RDBMS used by the cluster fails, then what? The answer is obvious -- the cluster can no longer be utilized because the RAM and disk parts go out of sync.
- SQL over RAM only. Apache® Ignite™ provides SQL database capabilities, however, you can only leverage them if all of the data and indexes are located in RAM. If a single piece of data, represented by a disk copy located in the RDBMS, then an Ignite-only SQL query will return an incomplete result set.
- Requried RAM warmup . When your cluster goes down, you have to restart it and preload all of the data from the RDBMS to RAM. That’s essential if you use SQL or similar advanced querying languages. This dramatically increases the overall time of the downtime and can cost a lot of money.
If you use either Apache Ignite 1.x or 2.0 along with the RDBMS for disk storage, then you will hit these limitations. It’s just the way in-memory architectures are integrated with the disk.
However, the limitations are no longer relevant for Apache Ignite 2.1! This version made a leap from in-memory to a memory-centric architecture that:
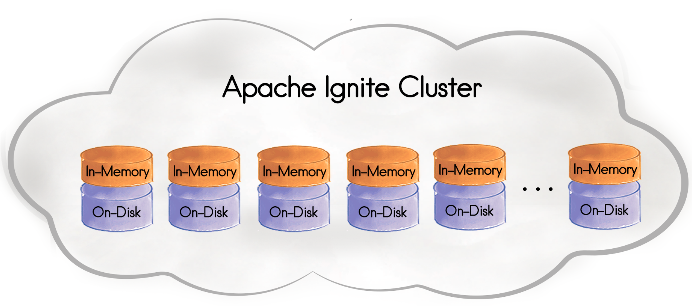
Curious about how Ignite achieved these huge advantages? Lifting the curtain….
Durable Memory Architecture
The Apache Ignite memory-centric platform is based on the durable memory architecture that allows storing and processing data and indexes both in-memory and on disk when the Ignite Persistent Store is enabled. The memory architecture helps to achieve in-memory performance with the durability of the disk using all of the resources available in the cluster.
The durable memory is built and operates in a way similar to the virtual memory of operating systems such as Linux. However, the one significant difference between these two types of architectures is that the durable memory one always keeps the whole data set and indexes on the disk -- if the Ignite Persistent Store is enabled -- while the virtual memory uses the disk for swapping purposes only.
Ignite Persistent Store
Persistent Store is a distributed ACID and SQL-compliant disk store that transparently integrates with the durable memory as an optional disk layer (SSD, Flash, 3D XPoint). Having the store enabled, you no longer need to keep all of the data in memory or warm-up the RAM after a whole cluster restart. The persistent store will keep the superset of data and all the SQL indexes on the disk making Ignite fully operational from the disk.
The Upshot
Tired of hooking up Ignite with an RDBMS? Go ahead and download Apache Ignite 2.1, enable Ignite Persistent Store, and launch your first durable Ignite cluster that distributes data sets and workloads relying on the performance of RAM and durability of the disk!
Finally, Apache Ignite 2.1 can boast about another achievements in .NET, C++, SQL and Machine Learning. Go ahead and discover them!